これからのAI戦略と展望
こんにちは。すっかり春らしくなってきたと思ったら、
突然雪が降ったりと、なかなか暖かい日々は続きませんね。
さて、今日は技術的な内容ではなく、
AIのこれからの展望と課題について、雑感を綴りたいと思います。
また、以下の文中ではAIという言葉を使用していますが、DeepLearningのこととして捉えてください。
AIへの期待の高まりとこれから
近年、毎日というくらいAI関連のニュースが飛び交い、AIというワードは世間に浸透してきました。その反面、自動運転に代表されるようにAIによって実現間近といわれてきた技術は鈍化がみられ、なかなか皆が思い描くような形では実現していません。
もっとも、自動運転については倫理的な問題も含んでいるため、単に技術だけの問題であるとは言えませんが。
今思い返してみると、4,5年前は全く違う状況でした。Googleが10万枚数の画像を学習し、
猫を認識できるようになったと発表した時、多くの人々がそれが何の役に立つのかと首を傾げたものでした。しかし、それから5年あまり、今日では、実社会の多くの場所で、AIは実用化されています。
それは、主にマーケティングや業務の最適化だったり、株価予測やセキュリティなど、主にIT関係の企業で行われてきました。
そして、今後は間違いなくそれ以外の産業でAIの活用が大幅に増えていくと予想されます。
つまりそれは、農水産業、建設業、サービス業などの非IT企業に大きな可能性があるということです。
AIの技術的な問題点として、現時点で100%の精度を出すAIは非常に困難で危険であるとも言えます。
何故ならば、AIの特性として、仮に100%の精度を出すAIを作れたとしても、
過学習や新規の問題に対する柔軟性が劣るなどの不安要素を抱えている可能性が高いからです。
逆に言えば、100%の精度が必要とされるところでは、それほど発展していかないのではと考えられます。
つまり、AIは完全なものではないという認識のもと、人間が行うよりも効率的で意味がある作業や産業に対していち早くソリューションを提供し、目に見える形で結果を出すということが、これからのAIにおける大きな戦略の一つだと言えると思います。
海外との差
これは残念ながら、現状大きな差があります。
私自身、海外のスタートアップに属しているため、日々痛感しています。
例えば、当たり前ですがAIに限らずほぼ全ての技術論文は英語で発表されます。
そして、新しいAIに関する論文が毎週というぐらい発表され、AIの能力は日々成長しています。
そういった状況で、英語から日本語に翻訳されるのを待っていたのでは遅すぎます。
また、海外との差はなにも技術的な問題ばかりではありません。
一番大きなものは、投資額とスピード感です。
アメリカにおいては非常にダイナミックで、日々、多額の投資がAI関連企業に対して行われています。
また、中国やシンガポールといった国では、国家レベルでAI技術に投資を行い
交通渋滞や様々な社会問題を解決しています。
これは、日本が未来に対してギャンブル的な投資を行うのをよしとしない社会であるということにも起因していますが、現在のAIに対する消極的な姿勢は、インターネット黎明期に多くの企業がその可能性を軽んじ、日本の電気メーカーをはじめ多くの企業が没落したいった時と重なる気がしています。
日本にとって、希望となるのはシリコンバレーで今、多額の投資を行い
猛威を振るっているのが、孫正義率いる、VisionFoundということでしょうか。
AI技術者の育成
日本が海外に対抗していく一つの解決策としては、AIの技術者を育成していくことだと思います。なぜなら、AIの技術はまだまだ黎明期であり、これからさらなる発展が望めるからです。
先日、チューリング賞の受賞が決まったジェフリー・ヒントン、ヤン・ルカン、ヨシュア・ベンジオらは、長いAIの冬の時代を経験し、多くの研究者に時代遅れと言われながらも、諦めずに研究を続けてきました。しかし、彼らは決して若くないため、これらの研究者に続く若い人材を育てていくことが必要です。
具体的には、東京大学の松尾先生達が行なっている、
実践的な教育を、もっと大きいスケールでやっていくことだと思います。
学生ではなく、これからAIを始めようとしている技術者または非技術者はどうすればいいのか。
一番早い方法は、WEBのオンラインコースでAIを勉強することです。
そして、実際の問題に取り組んでみることです。
例えば、分類問題や物体認識でも、チュートリアルを行うことと、実際の課題に取り組むことではとてつもなく大きな差があります。
なぜならば、チュートリアルではうまくいっていても、実際の課題に取り組むと必ず問題が出てくるからです。
先日、打ち合わせをした某大手電気メーカーのイノベーション担当の方もこんなことを言ってました。
「多くのスタートアップ企業に会っているが、その半分くらいは、
顔認識や行動解析のチュートリアルを行なっただけのものを
さも、どうだと言わんばかりに見せてきてうんざりしている」
驚くべきことですが、これが日本の現状です。
実際の問題に真剣に取り組み、乗り越えることで新たな知見を持つことができ、それが技術者にとっての資産になっていきます。
また、フレームワークとネットワークの理解のために、
KerasやTensorflowで書かれたモデルをPyTorchなどの異なるフレームワークで書き直してみる方法もおすすめです。
ある程度、自由にモデルを実装できるようになったら、新しい論文を読んで実装してみましょう。
論文を読むと、その時は分かった気になってしますのですが、実は身についていないことが多いです。
自分で論文を読み実装し、再現性を確認することで、フレームワークに慣れることもでき、数学的なアプローチも身につくことができます。
また、論文で発表されたモデルであっても、自由に実装できる技術があれば自分のアイディアを即座に試すことができ、結果、論文の精度を超えてしまったなんてことは、よくある話です。
広い視野とチャレンジ精神
では、今後日本がどのような戦略をもって、GAFAなどの世界中の企業と戦っていくのかというと
前述したように、AI技術者の育成を含め、既存の産業が持っている問題点を掘り起こし、
大きなチャレンジ精神で挑んでいくことだと感じています。
文章で書くと「なんだ、そんなことか」と思われがちですが、現在のAIはとにかくやってみるということがものすごく大切です。
その結果、大きな失敗もするでしょうが、その知見をもとに最終的に大きな成功へと導いていけばいいのです。
また、日本は幸か不幸か、高齢化や人手不足など、解決すべき社会問題が多く存在します。
そういった問題を、世界に先駆けてAI(を含めた技術)で解決していくことで、世界をリードすることが可能だと思っています。
広い視野を持ち、困難に立ち向かっていくことができれば、道は開けると信じて進んでいくべきです。
以上、自分自身への戒めも含めて、最近思っていることを綴りました。
PR: SosoguではAIを使用し問題解決に取り込もうとしている、企業、個人からのご連絡をお待ちしております。春なので、ぜひ一緒に面白いことを始めましょう!
ML-Engineを使ってDeep Learningのトレーニングを爆速化する
はじめに
Cloud Machine Learning Engine は、Googleが提供しているCloudのマシンラーニング環境です。 TensorFlow やKerasを使用して、大規模な機械学習モデルをトレーニングし、トレーニング済みのモデルをホストしてクラウド内の新しいデータに関する予測を行うことができます。
予備知識
ML Engineを扱うためには、ある程度のMachine LearningとTesnorflowの知識が必要です。
初めての方は、ローカルの環境でTensorflowで一度コーディングしてみることをお勧めします。
チュートリアル
これから書く内容は公式のチュートリアル の内容とほぼ同じです。
1. GCPプロジェクトの設定
まずはじめにGoogle Cloud Platformの設定を行います。
GCP プロジェクトを選択または作成します。[リソースの管理] ページに移動
プロジェクトに対して課金が有効になっていることを確認します。
課金を有効にする方法について
Cloud Machine Learning Engine と Compute Engine API(複数)を有効にする。ENABLE THE APIS
認証情報の設定:
GCP Console で [サービス アカウント キーの作成] ページに移動します。[サービス アカウント キーの作成] ページに移動
[サービス アカウント] プルダウン リストから [新しいサービス アカウント] を選択します。
[サービス アカウント名] フィールドに名前を入力します。
[役割] プルダウン リストで、[プロジェクト] > [オーナー] を選択します。
[作成] をクリックします。キーが含まれている JSON ファイルがパソコンにダウンロードされます。
環境変数 GOOGLE_APPLICATION_CREDENTIALS をサービス アカウント キーが含まれる JSON ファイルのファイルパスに設定します。
Linux または Mac OS
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
env:GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
Cloud SDK をインストールし、初期化します。
2. Python環境
オプションになりますが、pyenvとvirtualenvで仮想環境を作成して実行することをお勧めします。
例:
pyenv virtualenv python2.7 ml-engine-test
Tensorflowをインストールします。
pip install tensorflow
3. 準備
Githubのレポをクローンして
git clone https://github.com/GoogleCloudPlatform/cloudml-samples.git
estimatorフォルダーに移動します。
cd cloudml-samples-master/census/estimator
サンプルデータをダウンロードします。
mkdir data gsutil -m cp gs://cloud-samples-data/ml-engine/census/data/* data/
python依存関係のインストール
pip install -r ../requirements.txt
4. Google Storageバケットの設定
Project_ID, Bucket_Nameを設定します。
PROJECT_ID=$(gcloud config list project --format "value(core.project)")
BUCKET_NAME=${PROJECT_ID}-mlengineRegionはus-central1に設定してください。
REGION=us-central1
新しいバケットを作成します。
gsutil mb -l $REGION gs://$BUCKET_NAME
次に、データファイルとJsonファイルを Cloud Storage バケットにアップロードします。
gsutil cp -r data gs://$BUCKET_NAME/data gsutil cp ../test.json gs://$BUCKET_NAME/data/test.json
アップロードしたデータを変数指定します。
TRAIN_DATA=gs://$BUCKET_NAME/data/adult.data.csv EVAL_DATA=gs://$BUCKET_NAME/data/adult.test.csv TEST_JSON=gs://$BUCKET_NAME/data/test.json
5. Googleクラウドでのトレーニング実行
さあ、いよいよ準備が整ったので、トレーニングを実行します。
Job NameとOutput Pathを設定します。
JOB_NAME=census_single_1 OUTPUT_PATH=gs://$BUCKET_NAME/$JOB_NAME
以下のコマンドでトレーニングを実行します。
gcloud ml-engine jobs submit training $JOB_NAME \ --job-dir $OUTPUT_PATH \ --runtime-version 1.4 \ --module-name trainer.task \ --package-path trainer/ \ --region $REGION \ -- \ --train-files $TRAIN_DATA \ --eval-files $EVAL_DATA \ --train-steps 1000 \ --eval-steps 100 \ --verbosity DEBUG
問題がなければ、あっという間にトレーニングは終わるはずです。
結果のログは以下のコマンドで表示させることができます。
gsutil ls -r $OUTPUT_PATH
または、GCPコンソールで結果をクリックすることもできます。
まとめ
今回は、GoogleのMLEngineを使ってクラウドでトレーニングを行いました。
TensorflowやKerasの知識があれば、非常に高速にトレーニングを行うことができます。
AmazonやMicrosoftでも同様のサービスを提供していますが、
MLEngineは飛び抜けて高速にトレーニングできると感じました。TPU恐るべしです。
ローカルな環境でトレーニングを行うのは便利なのですが、
GPUは毎年アップデートされてく中で、その都度、高価なGPUを手に入れるのはコスパがよくありません。
今やクラウドサービスをうまく使って、効率よくトレーニングを行なって行くことが必要不可欠な時代ではないでしょうか。
Neural Networkベースのトラッキング手法GOTURNを使ってみる
はじめに
トラッキングとは簡単に言うと、カメラに写っている対象のオブジェクトを追跡して行くことです。マシンビジョンの世界では人間の行動解析や交通システム等で使用されている技術です。
実は昔、GOTURNはOpenCV3.2で試してみたのですが、その時はバグがあってうまく動きませんでした。
先日、既存のトラッキング手法プレビューしていて、ふとGOTURN思い出したので、今度はOpenCV3.4で試してみます。
実行環境
実行環境は以下の通りです。
C++
OpenCV: 3.4 + OpenCV_Contrib 3.4
OS: Ubuntu16.04
CPU: corei7-7700K
OpenCVは各自の環境に合わせてインストールしてください。
Pre-Trained モデルの入手
これはOpenCV-extraと言うモジュールの中にあります。
https://github.com/opencv/opencv_extra/tree/c4219d5eb3105ed8e634278fad312a1a8d2c182d/testdata/tracking
4つのZipファイルとファイルをgoturn.prototxtダウンロードします。
その後、以下のコマンドでZipファイルを1つに統合します。
cat goturn.caffemodel.zip* > goturn.caffemodel.zip
そして、ZIPファイルを以下のコマンドで解凍します。
unzip goturn.caffemodel.zip
goturn.caffemodelとgoturn.prototxtは実行フォルダに移動してください。
実行
顔をトラッキングした結果です。
うまく、トラッキングしていますね。
GOTURNの問題として、複数のトラッキングが出来ません。また、オクルージョンに対応していないので、木や建物でオブジェクトが遮られるとうまくトラッキング出来ないことがあります。
しかし、それ以外の場合は非常にロバストなトラッキングが行えます。
#include <iostream> #include <opencv2/opencv.hpp> #include <opencv2/tracking.hpp> #include <opencv2/core/ocl.hpp> using namespace cv; using namespace std; // Convert to string #define SSTR( x ) static_cast< std::ostringstream & >( \ ( std::ostringstream() << std::dec << x ) ).str() int main() { // Create a tracker Ptr<Tracker> tracker = TrackerGOTURN::create(); // Read video VideoCapture video("/path/to/video"); // Exit if video is not opened if(!video.isOpened()){ cout << "Could not read video file" << endl; return 1; } // Read first frame Mat frame; bool ok = video.read(frame); // Define initial boundibg box Rect2d bbox(287, 23, 86, 320); // Uncomment the line below to select a different bounding box bbox = selectROI(frame, false); // Display bounding box. rectangle(frame, bbox, Scalar( 255, 0, 0 ), 2, 1 ); imshow("Tracking", frame); tracker->init(frame, bbox); while(video.read(frame)){ // Start timer double timer = (double)getTickCount(); // Update the tracking result bool ok = tracker->update(frame, bbox); // Calculate Frames per second (FPS) float fps = getTickFrequency() / ((double)getTickCount() - timer); if (ok){ // Tracking success : Draw the tracked object rectangle(frame, bbox, Scalar( 255, 0, 0 ), 2, 1 ); }else{ // Tracking failure detected. putText(frame, "Tracking failure detected", Point(100,80), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0,0,255),2); } // Display tracker type on frame putText(frame, trackerType + " Tracker", Point(100,20), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(50,170,50),2); // Display FPS on frame putText(frame, "FPS : " + SSTR(int(fps)), Point(100,50), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(50,170,50), 2); // Display frame. imshow("Tracking", frame); // Exit if ESC pressed. int k = waitKey(1); if(k == 27){ break; } } }
まとめ
正直、実際の現場でトラッキングを行う場合にはGOTURNでは十分ではありません。
と言うのも、人間や車のトラッキングは複雑な環境(木や建物によってオブジェクトが見えなくなる箇所がある)で行うことが多く、対象も複数になる場合がほとんどだからです。
弊社でも、YOLOやSSDで物体認識した後に独自のトラッキング手法を組み合わせて実際の現場で使用しています。
しかし、手軽にNNベースのトラッキングを試したい場合には良い選択ではないでしょうか。
新しくなったYOLOv3を使ってみよう
はじめに
本当は、YOLOv2のチュートリアル(使い方から自作データセットの作成、トレーニングまで)を書こうと思ったのですが、
先日YOLOv3がリリースされたので、そちらを実際に動かしてみたいと思います。
YOLOとは
single shotの物体検出手法の一つです。似たような手法には先日紹介したFaster R-CNNやSSDがあります。
v3ではモデルサイズが大きくなったことに伴い、v2と比較して検出速度は若干低下しましたが、検出精度はより良くなりました。
一般的に精度と速度はトレードオフの関係にあり、若干の速度の引き換えでより高精度になったv3は良いアップデートと言えます。
現在のところ、YOLOv3は最も高速でなおかつ高精度な検出手法といえます。
ちなみにYOLOはYou only look onceの略でインスタなどでハッシュタグに使われるYou only live once=(人生一度きり)をもじったものです。
なかなか洒落が効いていていいネーミングですね。
v2とv3の違い
大きな違いとしては、v2の19層モデルに対してv3では53層のNeural Networkモデルを使用しています。
また、主な手法の違いを下記に3つピックアップします。
1. Softmax関数の禁止
分類問題においてSoftmaxは多くのモデルで使用されてきましたが、彼らの論文によると
それは、精度を改善する上で不必要な関数とのこと。代わりにロジスティック回帰によって分類を行います。
2. YOLOv3は3つの異なるスケールでボックスを予測します。
この3つの異なるスケールから特徴量を抽出し、Feature mapを作成します。
3. アップサンプリング
直前の2つのレイヤー層からFeature mapを取得し、それを2倍アップサンプリングします。
また、ネットワークの最初のLayerからFeature mapを取得し、要素別の追加機能を使用して前述のmapとマージします。
この方法では、Object Boxのより意味のある情報と細かい情報を取得するのに役立ちます。
詳しくは、こちらの論文を読んでください。
https://pjreddie.com/media/files/papers/YOLOv3.pdf
実際に動かしてみる
ほとんど公式のホームページに書いてあるとおりなのですが、先ずはレポジトリを Cloneします。
git clone https://github.com/pjreddie/darknet
次に、フォルダに移動して
cd darknet
makeするだけなのですが、その前に、Makefileを確認しましょう。
DefaultではGPU、CUDNN、OPENCVが無効になっているので、GPU環境で使う場合は以下のように変更します。
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=0
あとは、makeしてコンパイルを行います。
make
weightsファイルをダウンロードします。
wget https://pjreddie.com/media/files/yolov3.weights
サンプル画像で検出を行います。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg

v2との結果比較
YOLOv3 YOLOv2


画像だけ見るとあまり違いが無いように見えますが、実際には精度が大きく改善されているのが分かります。
また、v2ではtruckをcarとしても検出しているのに対して、v3では見事にtruckのみを検出しています。
| YOLOv3 | YOLOv2 |
| dog: 99% | dog: 82% |
| truck: 92% | car: 26% |
| bicycle: 99% | truck: 65% |
| bicycle: 85% |
YOLOv3では速度を少し犠牲にしましたが、より高精度な検出を可能としました。
少し前までは、オブジェクトの検出はとても難しい課題であり、検出時間もとても長くかかっていました。
しかし、Deep Learningの発展と共に、より高精度で短い時間で検出できるようになりました。しかも、それは、ほんの数年の間に起こりました。
これは非常に驚くべきことです。
オブジェクト検出は非常に研究の盛んな分野であり、これからますます発展してくでしょう。
そしてそれは、監視や追跡のみならず、現在進行形で様々な分野で応用されています。
Faster R-CNNを使ってリアルタイムオブジェクト検出をしてみよう
はじめに
こんにちは伊藤です。だいぶ久しぶりの投稿となってしまいました。。
さて、前回の記事ではObject Detectionの代表的な手法として3つ紹介しました。
今日はその中の一つである、Faster R-CNNを実際に動かしてみたいと思います。
Faster R-CNNとは
物体の候補検出もCNNで行うことにより高速化された手法です。もともとはFast R-CNNという手法が先に発表されましたが、
すぐ後に更に高速となったFaster R-CNNが発表されました。
より詳しい内容は論文を参照してください
https://arxiv.org/abs/1506.01497
やり方
オリジナルはCaffe の方ですがhttps://github.com/rbgirshick/py-faster-rcnn/tree/96dc9f1dea3087474d6da5a98879072901ee9bf9
Caffe はあまり使いたくないので、今回はKerasのバージョンを使います。
https://github.com/jinfagang/keras_frcnn
環境:Ubuntu16.04LTS、Python3.7.3、 Keras2.13
GPU: GTX-1080Ti
まずはじめにクローンし、フォルダに移動します。
git clone https://github.com/jinfagang/keras_frcnn.git
以下の、モジュールが必要なので事前にインストールしておいてください。
・tensorflow
・keras
・scipy
・cv2
この、Repoでは自動車マシンビジョンのためのデータセット「KITTI Vision Benchmark Suite」を事前に学習していますが、
VOC、COCOや自分のデータセットを以下のフォーマットで用意することでトレーニングが行えます。
/path/training/image_2/000001.png,599.41,156.40,629.75,189.25,Truck
トレーニングが終了したら、以下の予測してみましょう。
python test_frcnn_kitti.py
以上、簡単にFaster R-CNNを実行することができました。
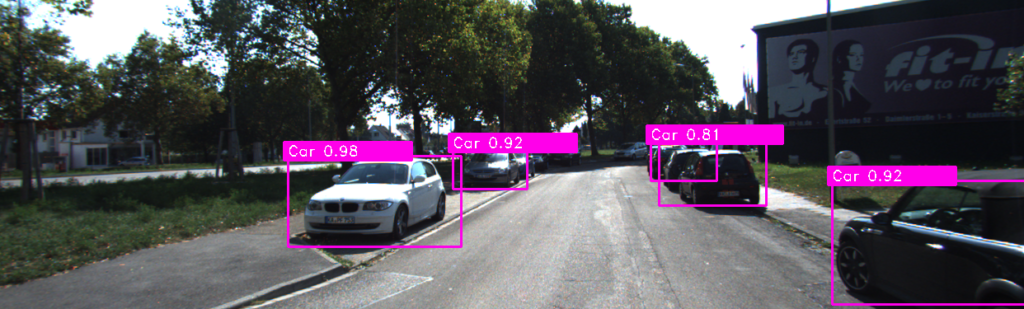
Deep Learningを使用した物体検出の方法
こんにちは伊藤です。
近年、人工知能が急速に注目を集めるようになってきましたが、
もともとは、Deep Learningが画像分類の問題を解く際に驚異的な精度を上げたことから始まっています。
画像分類とは、猫や犬の画像を見せてそれをコンピューターが自動で判断する類のものです。
これは、すでにコンピューターが人間の精度を凌駕して驚異的な成果を上げています。
しかし、実際には画像に写っているものを分類するだけではあまり実用的ではなく
IoTやマシンビジョンシステムの現場では、物体認識(画像に写っている物体の種類と位置を検出)する場合が多く発生します。
なぜなら、画像には他種類の物体が複数写っている場合が多いからです。
これは、監視カメラによる人物の特定や、自動運転の際に標識や歩行者を検出することを想像していただくとイメージしやすいかと思います。
そこで、今回は物体認識における3つの方法を紹介したいと思います。
1.Faster R-CNN
もともとはFast R-CNNという手法が先に発表されましたが、すぐ後に更に高速となったFaster R-CNNが発表されました。
このFast R-CNNのボトルネックとなっていた箇所は、Selective Searchでした。
(Selective Searchはピクセルレベルで類似する領域をグルーピングしていくことで候補領域を選出するルゴリズムです。
要は似たような特徴を持つ領域を結合していき、1つのオブジェクトとして抽出する訳です)
そこで、Faster R-CNNではRPN(Region Proposal Network)と呼ばれる非常に小さい畳み込みネットワークで
候補領域を検出する手法を発明しました。
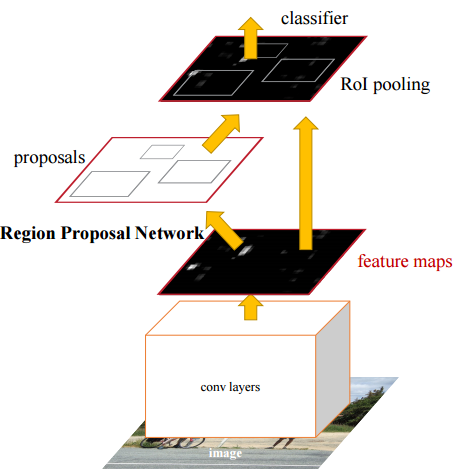
アスペクト比の変化やオブジェクトのスケールに対応するために、Faster R-CNNはアンカーボックスという概念を導入しています。
元の論文では、それぞれの場所でスケール128×128,256×256および512×512の3種類のアンカーボックスを使用します。
同様に、1:1,2:1と1:2の3つのアスペクト比を使用します。
したがって、合計でRPNがバックグラウンドまたはフォアグラウンドである確率を予測する9個のボックスを有することになります。
残りのネットワークはFast-RCNNに似ています。
VOC-2007のようなデータセットでの精度はほほ同様でありながら、Faster-RCNNはFast-RCNNよりも約10倍高速です。
そのため、Faster-RCNNは最も正確な物体検出アルゴリズムの1つです。
2.YOLO (You only look once)
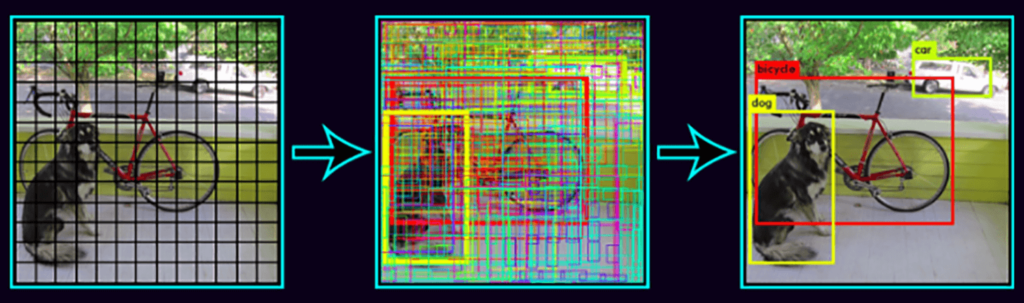
YOLOは、クラス確率とバウンディングボックスの座標を学習する単純な回帰問題です。
YOLOは各画像をS×Sのグリッドに分割し、各グリッドはN個の境界ボックスと信頼を予測します。
信頼度は、バウンディングボックスの精度と、バウンディングボックスが実際にオブジェクトを含むかどうか(クラスに関係なく)を反映します。
また、トレーニング中の各クラスの各ボックスの分類スコアを予測します。
両方のクラスを組み合わせて、各クラスが予測されるボックスに存在する確率を計算することができます。
したがって、合計SxSxNの非常に多くのボックスが予測されますが、これらのボックスのほとんどは信頼スコアが低く、例えばしきい値を30%と設定すると、
下の例に示すようにほとんどのものが削除されます。
3.SSD(Single Shot Detector)
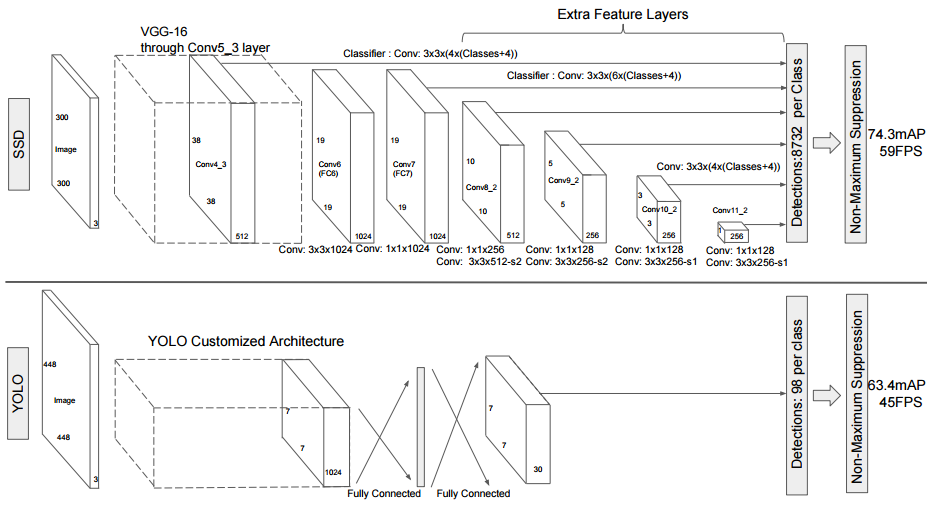
SSDは、入力画像上で畳み込みネットワークを1回だけ実行し、特徴マップを計算します。
この特徴マップ上に小さな3×3サイズの畳み込みカーネルを実行して、境界ボックスと分類確率を予測します。
SSDはまた、Faster-RCNNに類似した様々なアスペクト比でアンカーボックスを使用し、ボックスを学習するのではなくオフセットを学習します。
スケールを処理するために、SSDは複数の畳み込みレイヤの後のバウンディングボックスを予測します。
各畳み込みレイヤーは異なるスケールで動作するので、さまざまなスケールのオブジェクトを検出することができます。
YOLO(v1)との比較下に示します。YOLOは畳み込みを行ったあとにボックスの推定をしているのに対して、
SSDは中間層でバウンディングボックスの予測を行っています。
以上、3つの検出方法を紹介しましたが、それぞれの方法を使用する状況を考えたいと思います。
スピードがあまり要求されず、最高の検出精度が求められる場合はFaster R-CNNを使用するのがいいでしょう。
また、それほど演算能力のないデバイス上(Raspberry Piなど)で実行する場合はYOLOのTinyモデルを使うことがおすすめです。
SSDはその中間と言ったところでしょうか。
次回からは実際に3つの方法を実践して行きたいと思います。
それでは、今回はこの辺で。
Stay tuned.
近年、人工知能が急速に注目を集めるようになってきましたが、
もともとは、Deep Learningが画像分類の問題を解く際に驚異的な精度を上げたことから始まっています。
画像分類とは、猫や犬の画像を見せてそれをコンピューターが自動で判断する類のものです。
これは、すでにコンピューターが人間の精度を凌駕して驚異的な成果を上げています。
しかし、実際には画像に写っているものを分類するだけではあまり実用的ではなく
IoTやマシンビジョンシステムの現場では、物体認識(画像に写っている物体の種類と位置を検出)する場合が多く発生します。
なぜなら、画像には他種類の物体が複数写っている場合が多いからです。
これは、監視カメラによる人物の特定や、自動運転の際に標識や歩行者を検出することを想像していただくとイメージしやすいかと思います。
そこで、今回は物体認識における3つの方法を紹介したいと思います。
1.Faster R-CNN
もともとはFast R-CNNという手法が先に発表されましたが、すぐ後に更に高速となったFaster R-CNNが発表されました。
このFast R-CNNのボトルネックとなっていた箇所は、Selective Searchでした。
(Selective Searchはピクセルレベルで類似する領域をグルーピングしていくことで候補領域を選出するルゴリズムです。
要は似たような特徴を持つ領域を結合していき、1つのオブジェクトとして抽出する訳です)
そこで、Faster R-CNNではRPN(Region Proposal Network)と呼ばれる非常に小さい畳み込みネットワークで
候補領域を検出する手法を発明しました。
アスペクト比の変化やオブジェクトのスケールに対応するために、Faster R-CNNはアンカーボックスという概念を導入しています。
元の論文では、それぞれの場所でスケール128×128,256×256および512×512の3種類のアンカーボックスを使用します。
同様に、1:1,2:1と1:2の3つのアスペクト比を使用します。
したがって、合計でRPNがバックグラウンドまたはフォアグラウンドである確率を予測する9個のボックスを有することになります。
残りのネットワークはFast-RCNNに似ています。
VOC-2007のようなデータセットでの精度はほほ同様でありながら、Faster-RCNNはFast-RCNNよりも約10倍高速です。
そのため、Faster-RCNNは最も正確な物体検出アルゴリズムの1つです。
2.YOLO (You only look once)
YOLOは、クラス確率とバウンディングボックスの座標を学習する単純な回帰問題です。
YOLOは各画像をS×Sのグリッドに分割し、各グリッドはN個の境界ボックスと信頼を予測します。
信頼度は、バウンディングボックスの精度と、バウンディングボックスが実際にオブジェクトを含むかどうか(クラスに関係なく)を反映します。
また、トレーニング中の各クラスの各ボックスの分類スコアを予測します。
両方のクラスを組み合わせて、各クラスが予測されるボックスに存在する確率を計算することができます。
したがって、合計SxSxNの非常に多くのボックスが予測されますが、これらのボックスのほとんどは信頼スコアが低く、例えばしきい値を30%と設定すると、
下の例に示すようにほとんどのものが削除されます。
3.SSD(Single Shot Detector)
SSDは、入力画像上で畳み込みネットワークを1回だけ実行し、特徴マップを計算します。
この特徴マップ上に小さな3×3サイズの畳み込みカーネルを実行して、境界ボックスと分類確率を予測します。
SSDはまた、Faster-RCNNに類似した様々なアスペクト比でアンカーボックスを使用し、ボックスを学習するのではなくオフセットを学習します。
スケールを処理するために、SSDは複数の畳み込みレイヤの後のバウンディングボックスを予測します。
各畳み込みレイヤーは異なるスケールで動作するので、さまざまなスケールのオブジェクトを検出することができます。
YOLO(v1)との比較下に示します。YOLOは畳み込みを行ったあとにボックスの推定をしているのに対して、
SSDは中間層でバウンディングボックスの予測を行っています。
以上、3つの検出方法を紹介しましたが、それぞれの方法を使用する状況を考えたいと思います。
スピードがあまり要求されず、最高の検出精度が求められる場合はFaster R-CNNを使用するのがいいでしょう。
また、それほど演算能力のないデバイス上(Raspberry Piなど)で実行する場合はYOLOのTinyモデルを使うことがおすすめです。
SSDはその中間と言ったところでしょうか。
次回からは実際に3つの方法を実践して行きたいと思います。
それでは、今回はこの辺で。
Stay tuned.
Sosogu LLC. ブログ書きます
伊藤です。
Sosogu LLC. を創業して1ヶ月余が過ぎました。
私にとっては初めての起業だったため、この2ヶ月は準備や手続きで忙しくしていました。
先日、ほぼすべての必要な手続きを終え、会社として無事スタートを切ることができました。
Sosogu LLC.ではAI(人工知能)とマシンビジョンをコアテクノロジーとして
顧客に最適なソリューションを提供するとともに、新たなイノベーションを生み出していきます。
現在、AIの世界では日々多くのイノベーションが生まれています。
2012年に開催された画像認識コンテスト(Imagenet Challenge)で
カナダ・トロント大学のGeoffrey HintonらによるDeep Learningを使用した手法でこれまでにない飛躍的な成果を上げてからというもの
AIは突如としてイノベーションの最前線に位置づけられ、世界的なブームになりました。
当初は、AIにをどう実世界に生かしていくか、多くの企業が手探りの中模索していた状態が続きましたが
近年は自動運転、セキュリティ、音声解析、など実社会での実用例が多く挙げられるようになりました。
やってみたかったけど今までできなかった事が実際にAIできるようになってきています。
AIには多くの未知の可能性があり、様々な産業に掛け合わせることで多くのイノベーションが生まれていくと確信しています。
このブログでは会社のニュースや人工知能に関するコーディング方法や最新技術を投稿していきます。
また、技術的な内容ばかりではなく、たまには息抜きになるような内容も書いていきたいと思います。
皆様からのフィードバックをお待ちしております!
Sosogu LLC. を創業して1ヶ月余が過ぎました。
私にとっては初めての起業だったため、この2ヶ月は準備や手続きで忙しくしていました。
先日、ほぼすべての必要な手続きを終え、会社として無事スタートを切ることができました。
Sosogu LLC.ではAI(人工知能)とマシンビジョンをコアテクノロジーとして
顧客に最適なソリューションを提供するとともに、新たなイノベーションを生み出していきます。
現在、AIの世界では日々多くのイノベーションが生まれています。
2012年に開催された画像認識コンテスト(Imagenet Challenge)で
カナダ・トロント大学のGeoffrey HintonらによるDeep Learningを使用した手法でこれまでにない飛躍的な成果を上げてからというもの
AIは突如としてイノベーションの最前線に位置づけられ、世界的なブームになりました。
当初は、AIにをどう実世界に生かしていくか、多くの企業が手探りの中模索していた状態が続きましたが
近年は自動運転、セキュリティ、音声解析、など実社会での実用例が多く挙げられるようになりました。
やってみたかったけど今までできなかった事が実際にAIできるようになってきています。
AIには多くの未知の可能性があり、様々な産業に掛け合わせることで多くのイノベーションが生まれていくと確信しています。
このブログでは会社のニュースや人工知能に関するコーディング方法や最新技術を投稿していきます。
また、技術的な内容ばかりではなく、たまには息抜きになるような内容も書いていきたいと思います。
皆様からのフィードバックをお待ちしております!